
EnJinnier
[논문리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 본문
[논문리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
공학도진니 2024. 3. 23. 02:22트랜스포머의 등장 이후 트랜스포머 계열의 BERT, GPT, T5 등 다양한 사전 훈련된 언어 모델들이 계속해서 등장하고 있다.
그 중 가장 유명한 사전 훈련된 언어 모델 중 하나인 BERT를 담은 논문을 읽어보고자 한다.(이후 ALBERT, RoBERTa, ELECTRA와 같은 BERT의 파생 모델을 공부하는 방식으로 트랜스포머 계열 언어 모델에 대한 공부를 이어나가고자 함)
원문링크
https://arxiv.org/pdf/1810.04805.pdf
0. Background
BERT를 배우기에 앞서 워드 임베딩에서부터 ELMo, 그리고 트랜스포머에 이르기까지 자연어 처리가 발전되어온 흐름을 정리해보자.
1. 사전 훈련된 워드 임베딩
워드 임베딩 : 단어를 밀집 벡터로 표현하는 방법. 텍스트를 컴퓨터가 이해하고, 효율적으로 처리하게 하기 위해서 컴퓨터가 이해할 수 있도록 텍스트를 적절히 숫자로 변환하는 방법 중 하나.
다만, 하나의 단어가 하나의 벡터값으로 맵핑되므로, 문맥을 고려하지 못하여 다의어나 동음이의어를 구분하지 못한다는 문제점 발생.이러한 한계를 사전 훈련된 언어 모델(ELMo나 BERT)로 극복하고자 하였음(=>해결책)
2. 사전 훈련된 언어 모델
LSTM 언어 모델은 (사전 훈련된 워드 임베딩과 마찬가지로) 학습 전 사람이 별도 레이블을 지정해줄 필요가 없다. 따라서 방대한 텍스트로 LSTM 언어 모델을 학습해두면, 가중치가 랜덤으로 초기화 된 LSTM 모델보다 더 좋은 성능을 얻을 수 있다.
=> ELMo : 순방향 언어 모델과 역방향 언어 모델을 각각 따로 학습시킨 후, 이렇게 사전 학습된 언어 모델로부터 임베딩 값을 얻는다는 아이디어(이러한 임베딩은 문맥에 따라 임베딩 벡터 값이 달라지므로, 기존 워드 임베딩의 다의어 구분 불가 문제를 해결할 수 있음)
다만, LSTM의 성능을 뛰어넘는 트랜스포머의 등장으로 트랜스포머로 사전 훈련된 언어 모델을 학습하는 시도가 등장함.

(*Trm = Transformer)트랜스포머의 디코더는 LSTM언어 모델처럼 순차적으로 이전 단어들로부터 다음 단어를 예측함.(이걸 활용해 Open AI는 트랜스포머 디코더로 총 12개의 층을 쌓은 후에 방대한 텍스트 데이터를 학습시킨 언어 모델 GPT-1을 탄생시킴.)
이처럼 NLP의 주요 트렌드는 사전 훈련된 언어 모델을 만들고 이를 특정 태스크에 추가 학습시켜 해당 태스크에서 높은 성능을 얻는 것으로 접어들었음.이에 따라 언어 모델의 학습 방법에 변화를 주는 모델들이 등장함.
단방향 언어모델 vs 양방향 언어모델
일반적으로 지금까지 배운 전형적인 언어 모델은 모두 단방향 언어모델. (특정 단어를 예측하는 시점에서 양방향 언어모델은 역방향 언어 모델의 정보도 함께 받고 있기 때문에 미리 관측한 셈이 되므로 양방향은 구현하지 않음)하지만 언어의 문맥이라는것은 실제로 양방향이기 때문에, 그 대안으로 ELMo에서 순방향과 역방향이라는 두 개의 단방향 언어 모델을 따로 준비하여 학습하는 방법을 사용했음.이렇게 기존 언어 모델로는 양방향 구조를 도입할 수 없으므로
(맨 마지막에 무슨 단어가 나올까?
또는 이거 전에 무슨 단어가 나왔을까?
단방향이라면 둘 중 하나를 학습시킬 수 밖에 없음)
이후 양방향 구조를 도입하기 위해 새로운 구조의 언어 모델인 마스크드 언어 모델(Masked Language Model)이 탄생함.
3. 마스크드 언어 모델(Masked Language Model)
마스크드 언어 모델은 입력 텍스트의 단어 집합의 15%의 단어를 랜덤으로 마스킹 함.(*마스킹 : 원래의 단어가 무엇이었는지 모르게 한다.)그리고 인공 신경망에게 이렇게 마스킹 된 단어들을 예측하도록 한다.
(이 언어 모델에 대해서는 BERT의 본문을 공부하여 더 자세히 알아볼 예정)
1. BERT : Introduction
BERT는 2018년 구글이 공개한 사전훈련된 모델(Pre-trained Model)이다.
등장과 동시에 수많은 NLP 태스크에서 최고 성능을 보여주면서 명실공히 NLP의 한 획을 그은 모델로 평가받고 있다.
같은해인 2018년에 Google 퇴사자 출신이 만든 회사인 OpenAI에서 GPT-1을 발표하였다.지금의 챗지피티(지금 유명한 버전은 GPT-3임)의 시초가 된.. 엄청난 등장인데Generative Pretrained Transformer 의 이름에서부터 알 수 있듯 트랜스포머 기반의 사전학습된 모델이다. GPT는 대표적인 'left-to-right' 방식으로 훈련된 언어 모델이며, 가장 오른쪽에 어떤 토큰이 나올 확률이 높을지를 수없이 학습한다. (다음 논문은 GPT-1 논문을 리뷰할 계획이다.)
이에 맞서 구글에서 '양방향'으로 아이디어를 내 만든 것이 바로 BERT인 것이다.
BERT는 Bidirectional Encoder Representations from Transformers의 약자이며
Bidirectional에서 볼 수 있듯 "양방향의" 모델이다.
사실 당연하게도 어떤 단어를 추론하려면 앞 뒤 문맥을 모두 보는게(=양방향) 가장 유리하다.

(머신러닝에서는 Representation이라는 용어가 아주 자주 사용되는데, 자연어처리에서는 Representation을 '벡터'라고 바꿔서 보면
어려워보였던게 쉽게 이해될 때가 많다.)
아무튼, BERT는 결국
Bidirectional : 양방향 문맥 정보를 담은 토큰을
Encoder : 인코더를 통해
Representation from : 벡터(정보가 담긴 벡터가 된 토큰)로 만드는
Transformer : 트랜스포머 기반 모델라고 해석할 수 있다.
이제 BERT의 이름에 대해 해석할 수 있으니 BERT에 사용되는 기본적인 단계를 알아보자.
BERT는 크게 pre-training 단계와 fine-tuning 단계, 두 가지 단계로 구분한다.

Pre-training
단어 자체에서 알 수 있듯 BERT는 Pre-training, 사전학습 모델이며
레이블링 하지 않는 데이터를 기반으로 학습을 진행한다.
언어 모델을 Pre-training 하는 것은 자연어 처리 task의 성능을 향상하는데 있어 아주 효율적이다.
Feature-based & Fine-tuning
Feature-based
Fine-tuning
따라서 BERT가 높은 성능을 얻을 수 있었던 것은, 레이블이 없는 방대한 데이터로 사전 훈련(Pre-trained)된 모델을 가지고, 미리 학습한 파라미터들을 불러와 어떠한 레이블 된 태스크에 맞게 업데이트(Fine-tuning)(추가 훈련을 하여 하이퍼 파라미터를 재조정) 했기 때문이다.
처음에는 같은 Pre-trained 모델을 사용하지만, 풀고자 하는 문제에 맞게 Fine-tuning하게 되어 독립적인 모델이 만들어지는 것이다.

위의 그림을 예시로 한 번 더 이해해보자.
우리가 하고 싶은 태스크가 스팸 메일 분류라고 하였을 때, 이미 위키피디아 등으로 사전 학습된 BERT위에 분류를 위한 신경망을 한 층 추가한다. 이 경우, BERT가 언어 모델 사전 학습 과정에서 얻은 지식을 활용할 수 있으므로 스팸 메일 분류에서보다 더 좋은 성능을 얻을 수 있다.
2. BERT: Model Architecture
BERT는 앞서 정리했던 Attention is all you need 논문에서 제안한 Transformer의 Encoder-Decoder 구조 중
Multi-Layer Bidirectional Transformer Encoder를 사용하게 된다.
(* Transformer의 Encoder: 어떠한 문장이 입력으로 들어오면, 각 단어에 대한 Word embedding + Positional encoding을 수행한 뒤, 그 문장 안에 존재하는 서로 다른 단어들과의 관계를 Self-Attention으로 추출해 냅니다. 입력 문장 내의 다양한 특징을 반영하기 위해 여러 개의 Head로 나눈 뒤, 각 토큰과 입력 문장의 다양한 측면에서의 관계를 추출해 냅니다. 이를 Multi-head self-attention이라 합니다. 각기 다른 관계를 하나로 합친 뒤, 이후 Feed Forward Network를 거쳐 추가적인 특징을 학습하게 됩니다. 각 서브 레이어의 모든 출력 값에 정규화(Layer normalization)가 적용되고, 입력값과의 Skip-connection이 이루어집니다. 이게 하나의 Transformer layer이고, 실제 모델에서는 Layer를 여러 개 두어 Encoding이 진행됩니다.
출처: https://chloelab.tistory.com/25 [어차피 사는거 편하게 살자(어편살):티스토리] )
즉, BERT의 기본 구조는 트랜스포머의 인코더를 쌓아올린 구조이다.
논문에서는 2가지 종류의 BERT 모델을 크기를 기준으로 제안한다.
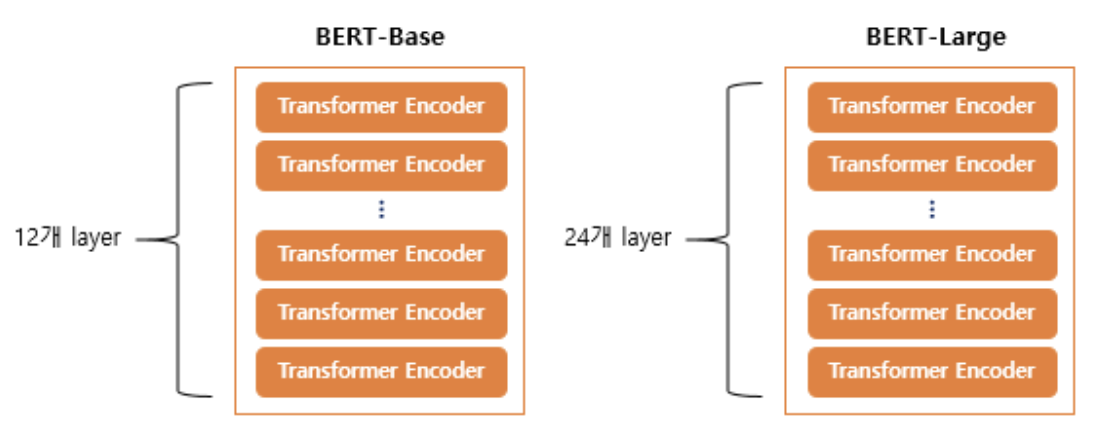
BERT-Base & BERT-Large
base버전에서는 총 12개를 쌓았으며, Large 버전에서는 총 24개를 쌓았다.
그 외에도 Large 버전은 Base버전보다 hidden size의 크기나 셀프 어텐션 헤드(Self Attention Heads)의 수가 더 크다.
- BERT-Base : L=12, H=768, A=12 : 110M개의 파라미터
- BERT-Large : L=24, H=1024, A=16 : 340M개의 파라미터
(초기 트랜스포머 모델 : L=6, D=512, A=8)
(참고로 BERT base는 GPT와의 비교를 위해 GPT-1과 동등한 크기로 설계하였으며 BERT-Large는 BERT의 최대 성능을 보여주기 위해 만들어진 모델이다.)
# Input/Output Representations
BERT의 입력은 앞서 배운 딥러닝 모델들과 마찬가지로 임베딩 층 (Embedding layer)를 지난 임베딩 벡터들이다.
각각의 정의된 hidden size(=d_model) 크기의 차원의 임베딩 벡터가 되어 BERT의 입력으로 사용된다.
(예를 들어, BERT-Base의 H=768이므로 각 768차원의 [CLS], I, love, you라는 4개의 벡터를 입력받아서(입력 임베딩) 동일하게 768차원의 4개의 벡터를 출력하는 모습(출력 임베딩)을 보여준다.)
BERT를 여러 자연어 문제에 적용하기 위해, 입력으로 들어오는 시퀀스가
하나의 문장인지, 두개 이상의 문장인지 명확하게 알 수 있어야 한다.
이를 파악하기 위해 [SEP] 라는 토큰을 사용한다.
( + 한 시퀀스 안에 등장하는 단어가 어떠한 문장에 속해있는지 알려주기 위해 Segment embedding 추가)
SEP 토큰 : 한 입력 시퀀스가 단일 문장인지 두 개의 문장이 합쳐져 있는지 알려주는 토큰.
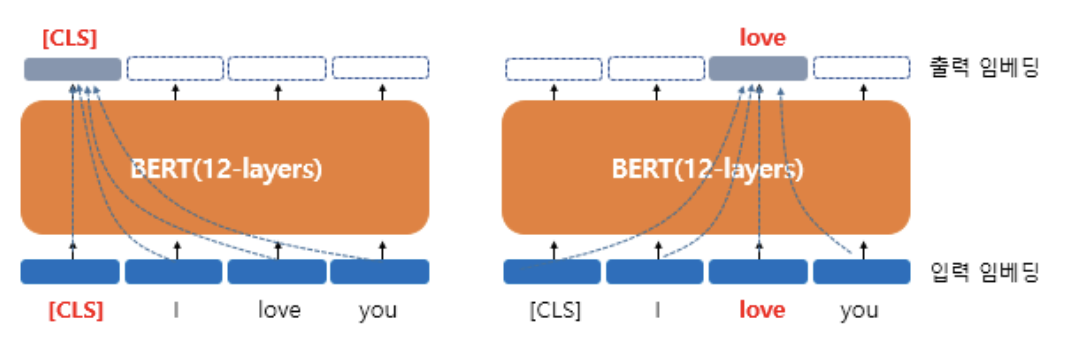
모든 입력 시퀀스의 첫 토큰은 [CLS] 벡터 (Classification Token)으로 시작한다.
CLS가 초기 입력으로 사용될때는 단순히 임베딩 층(embedding layer)을 지난 임베딩 벡터이지만, BERT를 지나고 나서는
[CLS], I, love, you라는 모든 단어 벡터들을 모두 참고한 후에 문맥 정보를 가진 벡터가 된다.

따라서 최종적으로, BERT는 2가지 방법으로 문장을 구별한다.
1. [SEP]이라는 특수 토큰을 이용해 문장을 둘로 나누어 구분.
2. 모든 토큰에 학습된 임베딩을 추가하여 입력 시퀀스를 구성하고 있는 토큰 중 어떤 토큰이 문장 A,B에 속해있는지 표시(= Sement Embedding)
(일반적으로 Segment Embedding을 적용할 때 그냥 Sentence A에 속하는 토큰에다가 0, Sentence B에 속하는 토큰에다가 1을 더해준다.)
주어진 토큰에 대해 각 토큰의 위치정보를 반영하는 Positional Embedding, 각 토큰이 어떤 문장에 속해있는지 알려주는 Segment Embedding, 각 토큰에 대한 Word Embedding인 Token Embedding의 값을 모두 합한 값이 그 단어의 최종 Input Embedding이 된다.
# Pre-training BERT
BERT는 사전학습 시 전통적인 left-to-right, right-to-left 방식(ELMo, GPT-1이 사용하는 방식)을 사용하지 않는다.
BERT가 사전학습을 하는 방법은 크게 두 가지이다.
1. Masked Language Model (MLM)
2. Next Sentence Prediction (NSP)
두 가지 모두 알아보자.
Task #1 : Masked LM
앞서 설명했듯, MLM은 학습할 모든 입력 토큰 중 일부(논문에서는 15%)를 mask하고, 이를 모델이 학습하여 맞추게 하는 것이다.
다만, fine-tuning 단계에서는 mask토큰을 사용하지 않기 때문에 mask만 사용할 경우 사전 학습 단계와 파인 튜닝 단계에서의 불일치가 발생하는 문제가 발생할 수 있다.
따라서 그 해결책으로
15%의 mask 예정 토큰 중 80%는 기존 mask 토큰, 10%는 random 토큰, 나머지 10%는 바꾸지 않고 기존의 토큰을 그대로 사용하게 한다.

그런 다음, 이를 가지고 원래의 토큰을 추측하게 한다.
이렇게 하면 BERT 입장에서는 각 단어가 변경된 단어인지 아닌지 모르므로 원래 단어를 예측해야 한다는 특징이 생기며
전체 문맥에 대한 흐름 이해를 유지할 수 있다는 장점이 있다.
Task #2 : Next Sentence Prediction (NSP)
BERT는 한 문장 내에서의 단어 뿐만 아니라 문장과 문장간의 관계도 이해해야 한다. (문장 간의 관계를 이해해야 하는 Question Answering(QA)나 Natural Language Inference(NLI) 가 있기 때문)
따라서 이러한 특징은 LM을 통해서 학습하기 쉽지 않기 때문에, NSP라는 task에 대해서도 함께 학습을 진행한다.
학습 과정은 다음과 같다.
1. 문장 A와 B를 pre-training 데이터에서 선택한다.
2. 50%는 실제로 이어져 있는 문장(IsNext)로 구성하고, 나머지 50%는 전혀 관계없는 문장(NotNext)로 구성한다.
3. 두 문장이 이어져 있는지 이어져 있지 않은지를 맞추게 한다.
다음 예시를 보면 앞서 말한 개념들에 대한 이해가 쉽다.

매우 단순한 task같아 보이지만, QA와 NLI task의 성능 향상에 매우 큰 도움이 된다.
참고로, BERT모델을 사전학습시키는데 사용한 데이터는 다음과 같다.
- BooksCorpus (800M words)
- English Wikipedia (2,500M words)
# Fine-tuning
앞서 설명한 두가지 방법을 통해 사전학습을 모두 끝냈으면, 이제 특정 task에 알맞게 모델을 update (=fine-tuning) 할 차례이다.
Fine-tuning 하는 방법은 간단하다.
Task에 알맞는 입력과 출력을 모델에 입력으로 제공해서 파라미터들을 해당 task에 맞게 end-to-end로 학습하여 업데이트한다.
이때, Transformer의 self-attention 덕분에 bidirectional이 가능해 입력으로 들어온 문자열 쌍을 한 번에 처리할 수 있으며,
문장 제일 앞에 도입했던 CLS 토큰을 이용해 Classification 문제를 풀 수 있다.
(CLS는 문장 내에 속하는 토큰이 아니고, 문장에 제일 앞에 위치해 모든 입력 시퀀스 전체를 바라볼 수 있는 효과를 가진다.)
따라서 Fine-tuning은 Pre-training 보다 비교적 시간이 오래 걸리지 않는다는 장점이 있다.)
3. Experiments
11개의 서로 다른 NLP 문제에 BERT를 적용해서 실험한 결과, 모두 SOTA를 달성했다!
각 실험에 대한 세팅은 논문에 자세하게 나와있으므로 여기선 생략하겠다.
# Effect of Pre-training Tasks

No NSP : maksed LM(MLM)으로만 학습하고 NSP는 사용하지 않은 경우
LTR & No NSP : left-to-right을 사용하도 NSP도 사용하지 않은 경우
두 경우 모두 MLM과 NSP를 모두 사용한 BERT-Base 모델에 비해 성능이 떨어지는 것을 확인할 수 있다.
# Effect of Model Size

모델의 크기가 fine-tuning 정확도에 어떤 영향을 주는지 확인.
L,H,A가 커질수록(모델의 크기가 커질수록) 좋은 성능을 제공하는 것을 볼 수 있다.
4. (개인적인) Conclusion..
이렇게 BERT는 Transformer를 이용해 다양한 NLP 문제를 처리할 수 있음을 알렸다.
다양한 task에 특화된 버전을 만들 수 있다는 장점이 있다는 것도 BERT가 사랑받은 이유 중 하나이다.
실제로 BERT는 승승장구 했다. (GPT-3가 나오기 전까지...)
BERT의 등장과 함께 자연어 연구에 전이 학습에 대한 연구가 쏟아져 나왔고, BERT의 장단점을 개선한 수많은 개량된 버전이 나왔다.
현재 최고의 성능을 보여주고 있는 모델은 BERT의 구조를 따르는 모델이 아닌
GPT-3나 T5-11B 이지만 아직까지 BERT의 개량된 버전이 나오는 이유는 GPT-3나 T5-11B는 엄청난 컴퓨팅 자원과 장비를 필요로 하기 때문에 더 스케일이 작아서 쉽게 접할 수 있다는 이유가 있다.
BERT 논문을 공부하며 지난번에 Transformer 논문을 공부하며 들었던 의문(QA나 Summary Task는 어떤식으로 처리되는지? 등)이 풀려서 재밌게 정리할 수 있었던 것 같다.
정리에 참고한 아주 고마운 글들
17-02 버트(Bidirectional Encoder Representations from Transformers, BERT)
* 트랜스포머 챕터에 대한 사전 이해가 필요합니다.  BERT(Bidire…
wikidocs.net
https://blog.naver.com/team_deot/223204877717
2023년에 보는 구글의 BERT (Pre-training of Deep Bidirectional Transformers for Language Understanding)
소개 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding http...
blog.naver.com
https://chloelab.tistory.com/25
[논문리뷰] BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Background Key features : NLP(Natural Language Processing), Language modeling objective, Transformer, Transfer learning, Masked Language Modeling(MLM), Next Sentence Prediction(NSP), Fine-tuning BERT는 유명한 논문입니다. LSTM 구조의 모델에
chloelab.tistory.com
https://misconstructed.tistory.com/43
[논문 리뷰] BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding (NAACL 2019)
2019년 구글에서 발표한 BERT에 대한 논문이다. 논문의 원본은 여기서 볼 수 있다. # Introduction Pre-trained Language Model은 자연어 처리 task의 성능을 향상시킬 수 있다. PLM(pre-trained language model)을 적용하
misconstructed.tistory.com
'딥러닝 > NLP' 카테고리의 다른 글
| [논문 리뷰] Generative Agents: Interactive Simulacra of Human Behavior (0) | 2025.01.17 |
|---|---|
| [논문 리뷰] Finetuned Language Models Are Zero-Shot Learners (0) | 2024.05.17 |
| [NLP] 바이트 페어 인코딩(Byte Pair Encoding, BPE) (0) | 2024.04.05 |


